linux从入门到删库(进阶篇)
linux从入门到删库(进阶篇)
现在开始进阶的指令,这些指令也是非常常用的
性能统计
cat /proc/cpuinfo
打印cpu详情
cat /proc/meminfo
打印内存详情
top
打印cpu负载与进程
 当一个进程申请内存时,操作系统会为其分配合适的虚拟内存空间,但只有当进程实际使用这些内存时,才会占用实际的物理内存。
当一个进程申请内存时,操作系统会为其分配合适的虚拟内存空间,但只有当进程实际使用这些内存时,才会占用实际的物理内存。
一些内存的性质:
VSS:分配但是未使用的内存+共享内存+特有内存
RSS:共享内存+特有内存
USS:特有内存
PSS:共享内存/n+特有内存 (相对于RSS更真实反应了)
共享内存就是几个程序都可能共同使用的内存,比如公用的库
free
打印内存使用信息
ps
ps算出来的cpu占用率是不准的,计算的是累计cpu占用率。
但是内存统计是很准确的
ps aux一般是查看性能使用ps -ef一般是关注进程本身
ps -a -o uid,pid,ppid,pcpu,pmem,rss,vsz,comm --sort -%mem | head -10
按关键字使用
netstat -tlnp t代表tcp l代办listen n代表不解析域名 p代表PID


netstat -tnp
当前 TCP 协议相关的网络连接情况
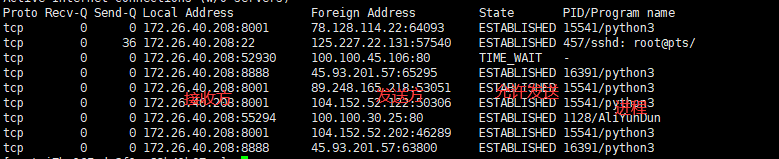
state就是状态,三次握手、四次挥手的不同状态
ESTABLISHED 成功连接 The socket has an established connection
SYN_SENT The socket is actively attempting to establish a connection
SYN_RECV A connection request has been received from the network.
FIN_WAIT1 The socket is closed, and the connection is shutting down.
FIN_WAIT2 Connection is closed, and the socket is waiting for a shutdown from the remote end
TIME_WAIT 主动关闭 The socket is waiting after close to handle packets still in the network
CLOSE The socket is not being used
CLOSE_WAIT 被动关闭 The remote end has shut down, waiting for the socket to close.
LISTEN The socket is listening for incoming connections
还有一个新的网络命令:ss 可以了解了解
ulimit -a 显示当前的句柄数等相关信息
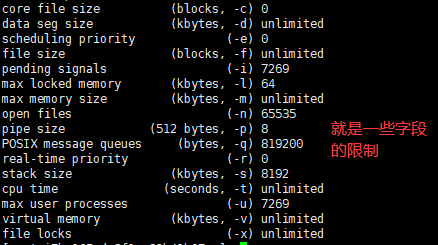
比如你建立连接受到限制,就到这里来找
显示内容效率指令
什么是效率指令? 能让我们更加便捷的指令。
你能想到的有什么?没错,排序、去重
sort 排序
cat test.txt | sort
这里的 | 是通道符,意思是左边输出的文字到右边输入,就是一个通道嘛,数据从左边到右边。
这个时候的排序是一个一个字符地比较:
133
22
1444
排序后:
133
1444
22
属性:
-n以数字进行排序
-h按照存储容量进行排序(KB、MB、GB)
-r按照逆序进行排列
-v按照版本号进行排序
-t指定分割符。默认为空格
-k指定为第几列排序
-f忽略大小写
-b忽略开头的空白字符
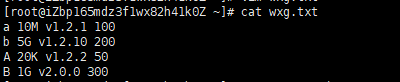




来个难一点的:
1.首先按存储容量大小进行排序(第二列)。
2.在存储容量相同的情况下,根据版本号排序(第三列)。
3.最后按照数字进行逆序排序(第四列)。

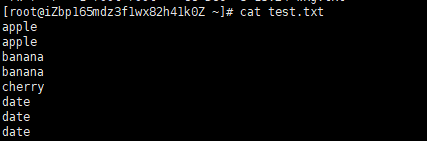
uniq 集合
-c统计出现的次数-d所有临近的重复的行只被打印一次(只打印两次及以上的)-D所有临近的重复的行全部被打印(只打印两次及以上的)-f跳过对前n个列的比较-s跳过对前n个字符的比较-w只对每行前n个字符进行比较



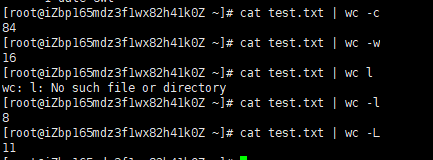
wc统计数量指令
-c 统计字节数
-l 统计行数
-w 统计不同的单词数
-L 打印最长长度
数据检索工具 grep
grep 强大的数据检索
支持正则表达式
常用做文本内容选择
常用属性:
-o 只显示你查找的内容(比如你查找wxg那只显示wxg)
-An n代表数字 显示查找内容及前n行
-Bn n代表数字 显示查找内容及后n行
-Cn n代表数字 显示查找内容及前后n行
-r 实现在文件夹中查找
-i 忽略大小写
-v 显示除了查找之外的
-n 在前面显示行数
-E 不用进行正则转义

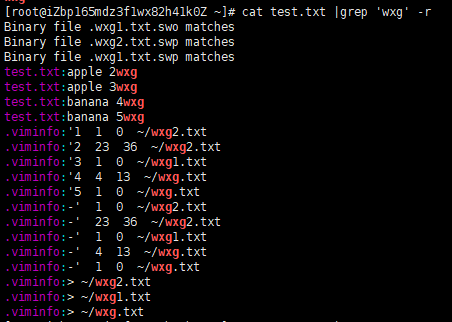
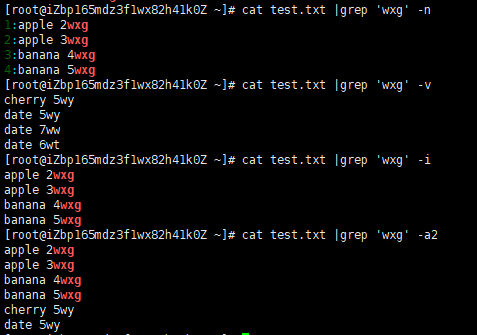
这些是简单的运用
有一个特殊情况:
当需要查找某个进程的时候:
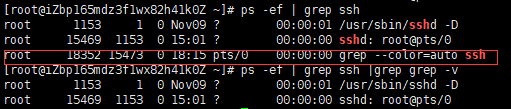
你调用grep这个指令也算一个进程。
所有显示会多一个grep的进程。
最强大的数据处理工具 awk
awk 数据处理工具
awk [options] ‘Pattern{Action}’ file
一定注意是单引号!
首先是options 也就是属性
-v 对默认变量进行更改

Pattern 叫行为,一般使用就两种:
BEGIN
END
一个是在之前,一个是之后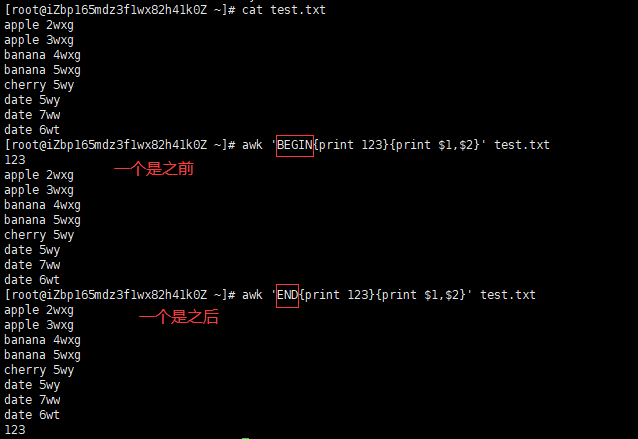
基本使用
打印行列数
awk '{print NR}' test.txt 打印行数
awk '{print NF}' test.txt 打印最大列数
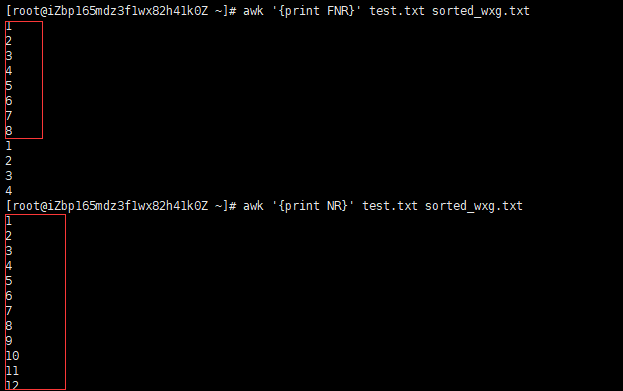
awk '{print FNR}' test.txt 分开打印所有的文件的行数
第三个有点抽象,就是打印的时候是分开来打印的
打印列数内容
awk '{print $n}' 其中n代表列数
awk'{print $NF}' 这个怎么理解 NF是内置变量,也就是最后一列
awk '{print $(NF-1)}' 这个就是打印倒数第二列
打印行数内容
awk 'NR>=2 && NR<=5' test.txt 打印第2到第5
字段检索
awk '/123/' 查找包含123的字段
awk '$2~/wxg/' 在第2列检索 wxg
awk '$2~/^w/' 在第2列检索 以w开头的
awk '$2>18' 查找第二列中大于18的
awk '/aa/,/bb/' 字段范围输出

分隔符的使用
awk -v -FS='#' '{print $2}' 替换默认分割符
awk -v -OFS ='!' '{print $1,$2}' 这里一定要这样写$1,$2,不能写$0 或者留空,实现输出分隔符的修改
编辑修改工具 sed
打印行数
sed -n '1,2p' test.txt 表示打印1~2行 类似于 awk 'NR>=1 && NR<=2' test.txt p就是print的意思,如果没有-n就会全打印,因为sed 默认是全打印!
删除行
sed -n '1,2d' test.txt 表示删除1~2行 d就是delete的意思
替换
sed 's/a/A/' 将所以的a替换成A
sed 's/a$/123A/' 将a结尾的每行第一个替换成123A
sed 's/a/A/g' 加个g 将所有的都替换成a
位置添加
sed 's/a/123&123/g' 所有的a前后都加上123 &能代办原始符号
一些逆序输出的实现

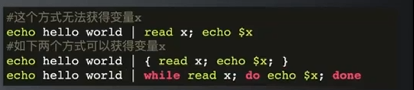
管道的一些小技巧
echo 123 | {read a; echo $x; }