

单元测试框架与自动化测试框架pytest
单元测试框架与自动化测试框架pytest
什么是框架?
解决一类问题的功能合集,需要按照规则或者套路进行。
单元测试的一个基本广泛称呼:xUnit
看一下它的标准架构:
Test runner
简单来说就是执行用例的一个方法
Test case
也就是测试用例
Test fixtures
这个可以称为夹具,你可以想象成一个夹子夹住我们的测试内容(其实和Test execution类似,但是它实现得更广泛一些)
Test suites
测试套件,也就是一些通用的共享的内容,通用的测试资源,用来管理、组装我们多个testcase测试用例
Test execution
测试执行
setup:运行前准备,可以分成模块级别、类级别、方法、函数级别
teardown:运行后收尾,一般用作数据回收
test result
也就是测试结果,可以有很多种格式,比如XML
Assertion
断言,也就是判断你的结果是否正确
现在java、python、go主流的测试框架:
java:
JUnit
testNG
python:
pytest
unittest
go:
go test
可以先了解了解什么是测试开发,这里有详细介绍:软件开发模型-从传统瀑布模型到DevPos | zhuozhuo测试小屋 (xgzhuozhuo.com)
简单来说,就是先写测试用例,便于后续开发的查缺补漏与规范
创建虚拟环境:
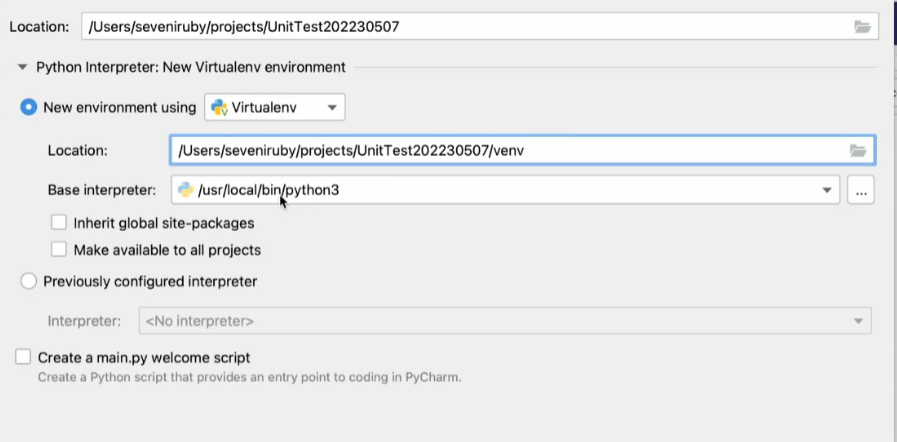 创建完成的python本质上是快捷方式:
创建完成的python本质上是快捷方式:
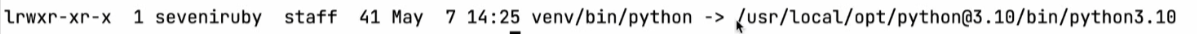 下载的软件包依赖会放在以下目录:
下载的软件包依赖会放在以下目录:

命令行想启动虚拟环境得输入以下内容:
.venv/bin/activate

接下来看看测试驱动开发的大概步骤:
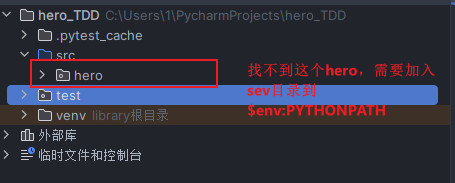
首先会有两个文件夹:
其实整体文件夹可能如下:
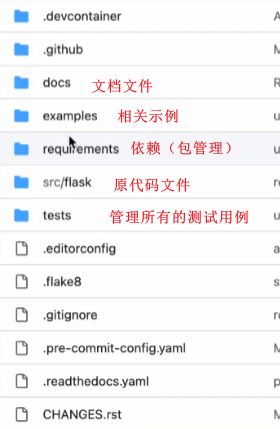
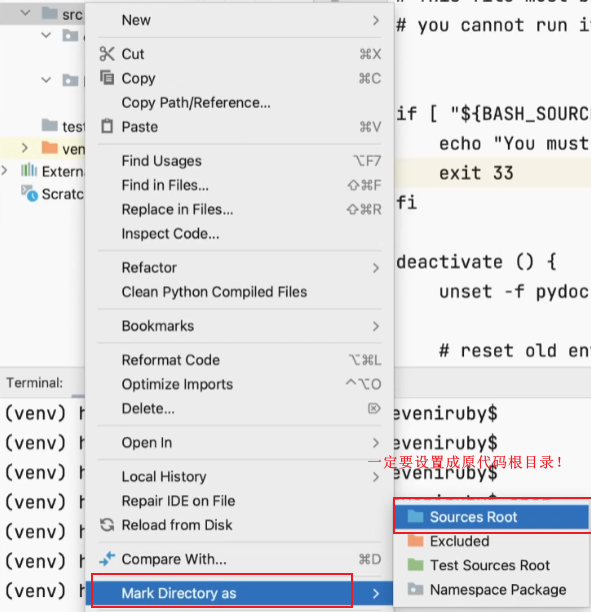
然后设计原代码文件:

一定要将原代码设置成源代码根目录!
sec内容一般会有:
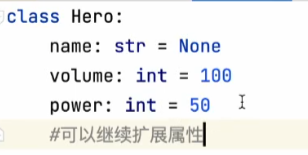
hero.py 记录英雄的属性值:
hero_Menager.py 记录英雄的一些方法
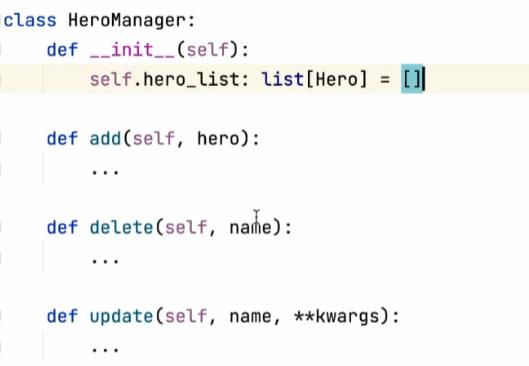
以上这两个我们也叫领域模型的设计
这个时候开发下一步就是写方法,每改一行代码都可以用一个测试体系,来保证整个功能的质量
在这之前就需要我们完成测试体系的构建!
先创建测试目录: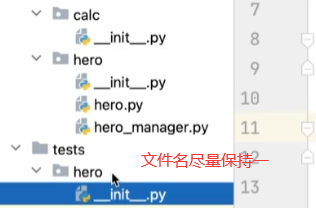
可以使用python的一个非常强大的生成能力:
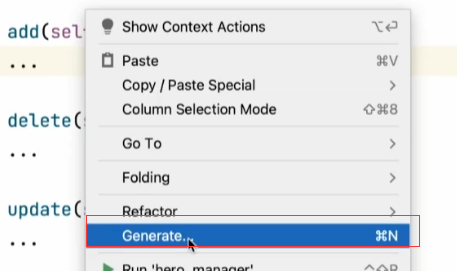
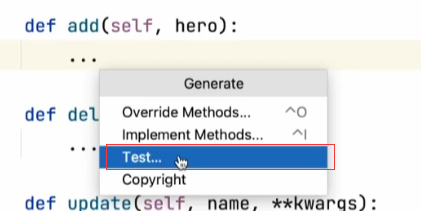
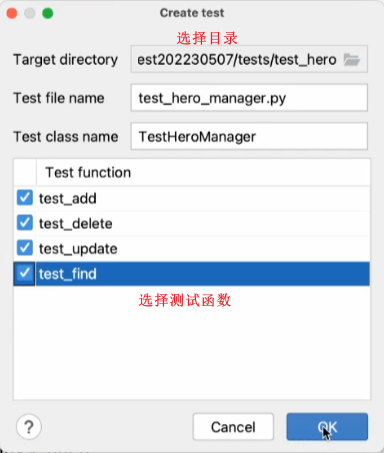
生成的内容是unittest,还不是pytest
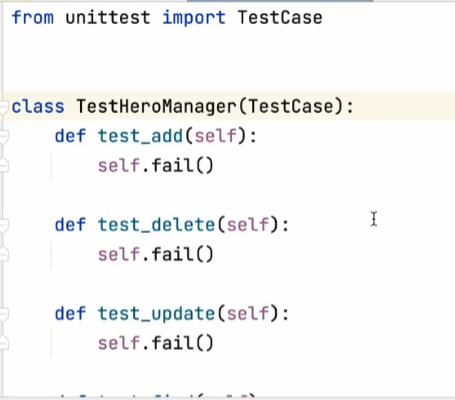
接下来就可以按照需求写测试用例。
需求需要传入什么值写什么值,断言输出值是否正确,基本上就ok了。


pytest正式开始:
为什么使用pytest?
1.pytest是python的测试框架,可以用来做简单的单元测试和复杂的功能测试
2.一般和selenium、request、appium等测试库一起配合使用完成自动化测试
3.pytest还支持300+的插件,适用各种场景,有各种方便的用法
4.功能强大,使用简单(比如测试用例可以写在类外)
那为什么不用unittest?
unittest 是内置的,功能有限
pytest可以兼容unittest
安装pytest
pip install pytest
文件命名规则:
文件命名规则:以
test_开头、或者以_test结尾类命名规则:以
Test开头函数、方法命名规则:以
_test开头
命名规则其实可以改:
在pytest.ini中添加以下内容,可以添加Check_规则:
python_files = check_* test_*
python_classes = Test* Check*
python_functions= test_* check_*
注意!测试类中不可以添加__init__函数!
setup and teardown
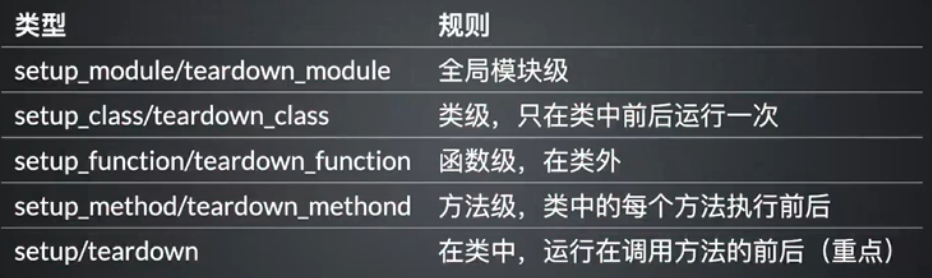 使用最多的还是
使用最多的还是
第2行和最后一行
参数化
单参数:@pytest.Mark.parametrize("参数名",[“参数”,“参数2”,”参数3“,”参数4“])多参数:@pytest.Mark.prarametrize("参数名,参数名",[[参数1.1,参数1.2],[参数2.1,参数2.2]])参数改名(ids):
@pytest.Mark.prarametrize("参数名,参数名",[[参数1.1,参数1.2],[参数2.1,参数2.2]]),ids=["命名1",“命名2”]实现中文用例显示:
# 创建conftest.py 文件 ,将下面内容添加进去,运行脚本
def pytest_collection_modifyitems(items):
"""
测试用例收集完成时,将收集到的用例名name和用例标识nodeid的中文信息显示在控制台上
"""
for i in items:
i.name=i.name.encode("utf-8").decode("unicode_escape")
i._nodeid=i.nodeid.encode("utf-8").decode("unicode_escape")笛卡尔积(参数组合):
@pytest.Mark.parametrize("参数名1",[“参数”,“参数2”,”参数3“,”参数4“])
@pytest.Mark.parametrize("参数名2",[“参数”,“参数2”,”参数3“,”参数4“])
def func("参数名1,参数名2"):
pass执行顺序:(下1上1)(下1上2)(下1上3)(下1上4)(下2上1)(下2上2)。。。。
用例归类:
@pytest.mark.归类名1需要在pytest.ini添加以下内容:
[pytest]
markers=归类名1
归类名2运行归类好的用例:
pytest 文件名.py -vs -m "归类名"主要是-m参数
跳过用例:
@pytest.mark.skip@pytest.mark.skip(reason=代码未开发完全)条件跳过:
这个是如果之前没有运行登录模块,则跳过该用例
f not check_login():
pytest.skip("unsupported configuration")
@pytest.mark.skipif(a==b,reason="a is not b")
预期为fall
@pytest.mark.xfailwindows终端运行:
首先进入测试目录:
cd 文件夹名称
dir 显示当前文件
运行的时候要注意!
如果出现找不到包():
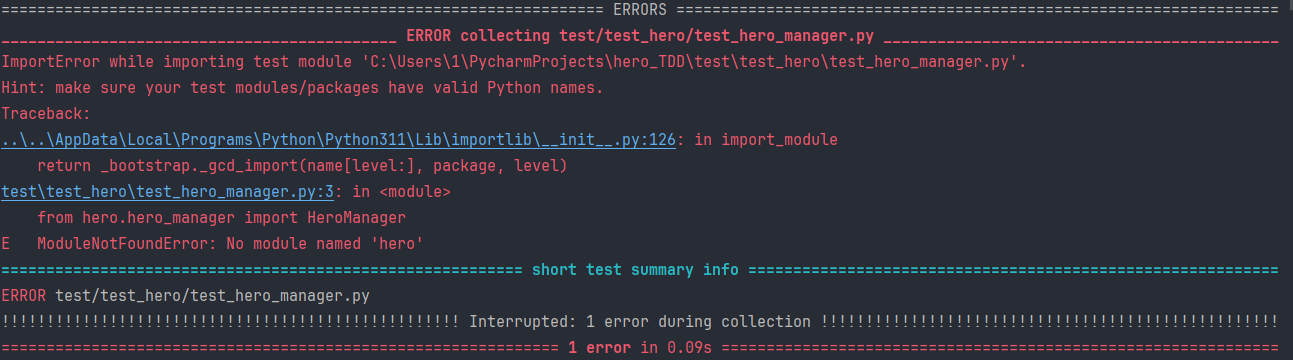 得设置 $env:PYTHONPATH 的值,在根目录命令行输入:
得设置 $env:PYTHONPATH 的值,在根目录命令行输入:
$env:PYTHONPATH = "$(pwd)\src"
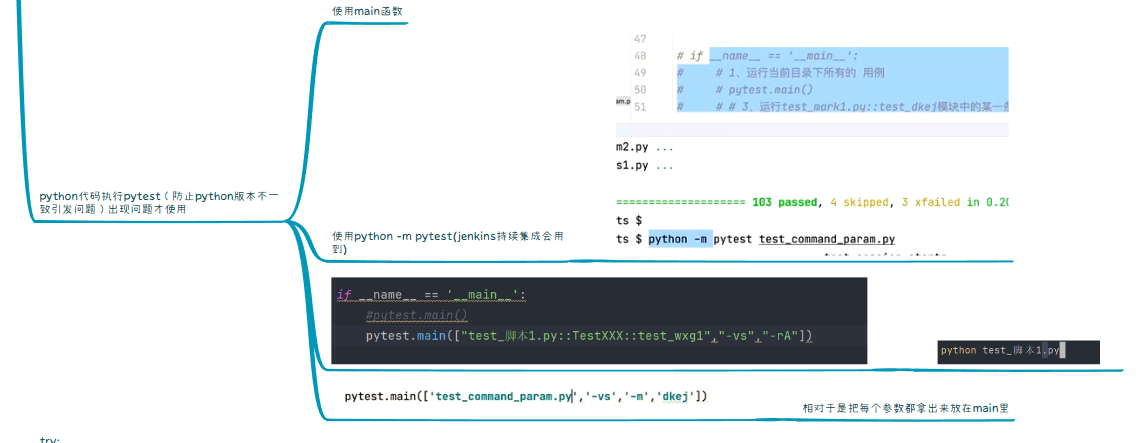
运行全部用例直接 pytest
运行特定用例 pytest::class类名::方法名 -v
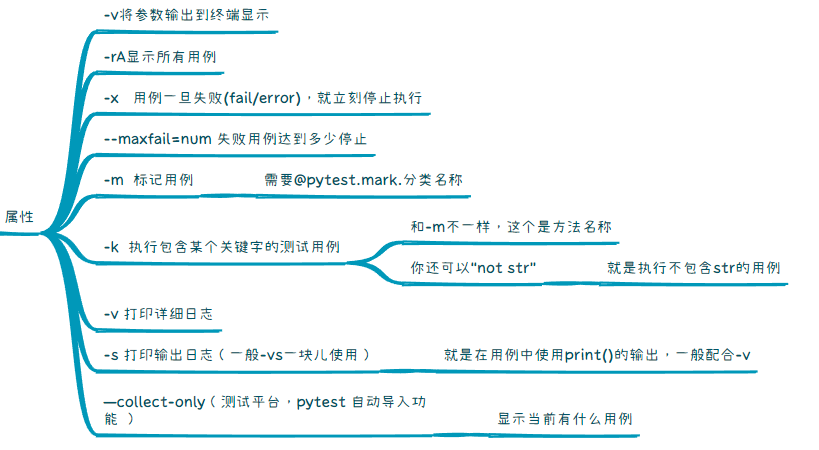
使用缓存状态:

python 执行pytest:
异常处理
1.使用try...except
try:
可能产生异常的代码块
except [ (Error1, Error2, ... ) [as e] ]:
处理异常的代码块1
except [ (Error3, Error4, ... ) [as e] ]:
处理异常的代码块2
except [Exception]:
处理其它异常2.使用pytest.raises(错误类型) as 别名: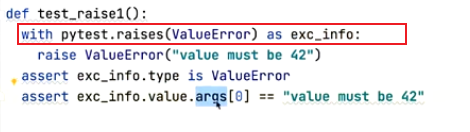
数据驱动:
实际上就是将文件先转换成嵌套数组[[]],然后再使用参数化:
.yaml
文件格式:
-
- 1
- 2
- 3
-
- 2
- 3
- 5
-
- 4
- 3
- 6使用方法:
#Utils.py文件
import os.path
import yaml
class Utils:
@classmethod
def read_yaml(cls,path):
abspath=os.path.dirname(os.path.dirname(os.path.dirname(os.path.abspath(__file__))))#找到根目录绝对路径
path=os.path.join(abspath,path)#拼接路径
with open(path,encoding="utf-8")as file:
data=yaml.safe_load(file)
return data@pytest.mark.parametrize("name,volume,power", Utils.read_yaml("data/heros_data.yaml"))
def test_add_hero(self, name, volume, power):
"""
测试名称:对添加英雄是否正常
:param name:
:param volume:
:param power:
:return:
"""
pre = len(self.Manager.hero_list)
self.Manager.add_hero(name, volume, power)
assert len(self.Manager.hero_list) == pre + 1.xlsx (excel)
文件格式:
1 2 3
2 4 6
3 2 6

使用方法:
import openpyxl
import pytest
from py_test1.func.add_func import Calculator
def change_to_list(cells):
demo = []
for i in cells:
demo1 = []
for f in i:
demo1.append(f.value)
demo.append(demo1)
return demo
def get_excal_data():
excel = openpyxl.load_workbook("../data/testdata_excel.xlsx")
excel_table = excel.active
cells = excel_table["A1":"C3"]
list_data = change_to_list(cells)
return list_data
class TestExcelGetData:
@pytest.mark.parametrize("a,b,c", get_excal_data())
def test_excal_data_add(self, a, b, c):
demo = Calculator()
assert demo.add(a, b) == c.csv
文件格式:
data1,data2,data3
1,2,3
2,3,4
2,4,6使用方法:
import csv
import pytest
from py_test1.func.add_func import Calculator
def test_get_csv_data():
data_list = []
with open("../data/csvdata.csv", "r", encoding="utf-8") as f:
data = csv.reader(f)
# 这里注意缩进
for i in data:
print(i)
data_list.append(i)
data_list.pop(0)
print(data_list)
return data_list
class TestCsvDataAddFunc:
@pytest.mark.parametrize("a,b,c", test_get_csv_data())
def test_csv(self, a, b, c):
demo = Calculator()
assert demo.add(int(a), int(b)) == int(c)
.json
文件格式:
{
"case1": [1,2,3],
"case2": [1,4,5],
"case3": [2,2,6]
}使用方法:
import json
import pytest
from py_test1.func.add_func import Calculator
def test_data_form_json():
with open("../data/jsondata.json","r",encoding="utf-8") as f:
data=json.loads(f.read())
# demo=[]
# for v in data.values():
# demo.append(v)
# return demo
return list(data.values())
class TestAddFunc:
@pytest.mark.parametrize("a,b,c",test_data_form_json())
def test_add_func_json(self,a,b,c):
demo=Calculator()
assert demo.add(a,b)==c
fixture的简单运用(其实能不用就不用,不利于理解其他框架)
conftest.py
# 创建conftest.py 文件 ,将下面内容添加进去,运行脚本
import pytest
def pytest_collection_modifyitems(items):
"""
测试用例收集完成时,将收集到的用例名name和用例标识nodeid的中文信息显示在控制台上
"""
for i in items:
i.name=i.name.encode("utf-8").decode("unicode_escape")
i._nodeid=i.nodeid.encode("utf-8").decode("unicode_escape")
@pytest.fixture
def login():
print("登录")
token = "213131"
yield token
print("登出")实际test_文件:
import pytest
"""
setup 操作
yield 返回值
teardown 操作
"""
#login放在conftest中
def test_search(login):
print(login)
print("搜索")
def test_cart(login):
print("购物车")
print(login)测试报告 Allure
首先需要安装 allure-pytest 包,可以使用 pip 命令进行安装:
pip install allure-pytestStep 2: 执行 pytest
pytest --alluredir=./allure-resultsStep 3: 生成报告
所有测试用例运行完毕后,可以执行以下命令生成 allure 测试报告:
allure generate ./allure-results -o ./allure-report --clean其中,-o 参数用于指定报告输出目录,--clean 参数用于在生成报告之前删除先前生成的报告,以确保报告数据是最新的。
直接在网页生产:
allure serve ./allure_results扩展:
使用junit的格式生成(现在很多测试报告都支持junitxml格式生成测试报告)也是现在的行业标准和规范,推荐使用
pytest --junitxml junit.xml --alluredir=./allure-results、
