

(五)UI 自动化测试selenium
UI 自动化测试selenium(五)
日志
1. 记录代码的执行记录,方便复现场景
2. 可以作为bug依据截图
1. 断言失败或成功截图
2.异常截图达到丰富报告的作用
3. 可以作为bug依据page source
1. 协助排查报错时元素当时是否存在页面上
创建一个log_utils.py文件
# 日志配置
import logging
# 创建logger实例
logger = logging.getLogger('simple_example')
# 设置日志级别
logger.setLevel(logging.DEBUG)
# 流处理器
ch = logging.StreamHandler()#将日志打印在终端
ch.setLevel(logging.DEBUG)
# 日志打印格式
formatter = logging.Formatter\
('%(asctime)s - %(name)s - %(levelname)s - %(message)s')
# 添加格式配置
ch.setFormatter(formatter)
# 添加日志配置
logger.addHandler(ch)文件打印:
import logging
# 创建logger实例
logger = logging.getLogger('simple_example')
# 设置日志级别
logger.setLevel(logging.DEBUG)
# 文件处理器
fh = logging.FileHandler('example.log',encoding="utf-8")
fh.setLevel(logging.DEBUG)
# 日志打印格式
formatter = logging.Formatter('%(asctime)s - %(name)s - %(levelname)s - %(message)s')
# 添加格式配置
fh.setFormatter(formatter)
# 添加文件处理器到logger
logger.addHandler(fh)使用实例:
class TestBaidu:
def teardown(self):
# 关闭浏览器驱动
self.driver.quit()
def setup(self):
# 实例化浏览器驱动
self.driver = webdriver.Edge()
# 隐式等待
self.driver.implicitly_wait(10)
# 跳转页面
self.driver.get("https://www.baidu.com/")
def test_search(self):
"""
测试百度搜索功能
前置条件:
1.网络正常
2.进入百度搜索页面
测试步骤:
1.输入框输入selenium
2.点击搜索
3.检查搜索结果是否包含对应关键字
后置条件:
1.关闭浏览器驱动
"""
# 定位标题元素,并输入内容
key="selenium"
self.driver.find_element(By.CSS_SELECTOR, '[id="kw"]').send_keys(key)
logger.debug(f"搜索的内容为 {key}")#输出搜索内容
# 点击搜索
self.driver.find_element(By.CSS_SELECTOR, '[id="su"]').click()
# 找到显示内容标题
title = self.driver.find_element(By.CSS_SELECTOR, 'em')#这里会找到第一个em元素
# 断言是否含有对应内容
# 到这一步可以使用断点debug,来找到对应元素的属性名
self.driver.save_screenshot("./baidu_search.png")#输出图片
logger.info(f"selenium in {title.text}")#输出info
assert "selenium" in title.text# 在报错行前面添加保存page_source的操作
with open("record.html", "w", encoding="u8") as f:
f.write(self.driver.page_source)报错当前页面的html,可方便我们对源码进行检查(用处不是特别大)
POM模式
什么是POM模式?
简单来说就是将重要的或者重复性高的测试步骤进行封装成对象,可以将测试脚本中的业务逻辑与UI代码分离
其实就是面向对象的思想
# login_page.py
from selenium import webdriver
from selenium.webdriver.common.by import By
class LoginPage:
USERNAME_ELEMENT=(By.ID, 'username')
PASSWORD_ELEMENT=(By.ID, 'password')
LOGIN_BUTTON_LELEMENT=(By.ID, 'login_button')
def __init__(self, driver):
self.driver = webdriver.Chrome()
self.username_field = self.driver.find_element(*USERNAME_ELEMENT)
self.password_field = self.driver.find_element(*PASSWORD_ELEMENT)
self.login_button = self.driver.find_element(*LOGIN_BUTTON_LELEMENT)
def enter_username(self, username):
self.username_field.send_keys(username)
def enter_password(self, password):
self.password_field.send_keys(password)
def click_login(self):
self.login_button.click()
# 在测试脚本中
def test_login():
driver = webdriver.Chrome()
login_page = LoginPage(driver)
login_page.enter_username("user1")
login_page.enter_password("mypassword")
login_page.click_login()
# 其他断言或操作优势:
降低 UI 变化导致的测试用例脆弱性问题
其实就是可维护性,一旦页面元素发生变化,只用修改对应的对象文件
让用例清晰明朗,与具体实现无关
建模原则:
字段意义
不要暴露页面内部的元素给外部
不需要建模 UI 内的所有元素
方法意义
方法应该返回其他的 PageObject 或者返回用于断言的数据
同样的行为不同的结果可以建模为不同的方法
不要在方法内加断言
class SearchPage:
__INPUT_SEARCH = (By.NAME, "q")
__BUTTON_SEARCH = (By.CSS_SELECTOR, "i.search")
__SPAN_STOCK = (By.XPATH, "//table//strong")
def __init__(self):
self.driver = webdriver.Chrome()
self.driver.implicitly_wait(3)
self.driver.get("https://xueqiu.com/")
def search_stock(self, stock_name: str):
self.driver.find_element(*self.__INPUT_SEARCH).send_keys(stock_name)
self.driver.find_element(*self.__BUTTON_SEARCH).click()
name = self.driver.find_element(By.XPATH, "//table//strong").text
return name异常自动截图功能
异常时,截图和打印page_source
实现方法:
try except 配合截图、page_source
import allure
from selenium import webdriver
from selenium.webdriver.common.by import By
import time
class TestTryCatch:
def test_try_catch(self):
self.driver = webdriver.Chrome()
self.driver.get("https://account.aliyun.com/")
try:
self.driver.find_element(By.ID, 'WE')
except Exception as e:
# 这里是一定要print的
print("出现异常:", e)
# 获取当前时间
time_stamp = int(time.time())
# 设置截图路径
screenshot_path = f"../data/screenshot/{time_stamp}.PNG"
page_source_path = f"../data/page_source/{time_stamp}.HTML"
# 报存截图
self.driver.save_screenshot(screenshot_path)
# 保存到测试报告
allure.attach.file(screenshot_path, name="screenshot", attachment_type=allure.attachment_type.PNG)
# 保存page_source
with open(page_source_path, "w", encoding="utf-8") as f:
f.write(self.driver.page_source)
# 保存到测试报告
allure.attach.file(page_source_path, name="screenshot", attachment_type=allure.attachment_type.HTML)
# 退出浏览器驱动
self.driver.quit()保存到测试报告
allure.attach.file(对应文件路径, name="文件名",attachment_type=allure.attachment_type.文件类型)
如果想显示的是源代码,HTML改成TEXT
输出到测试报告:
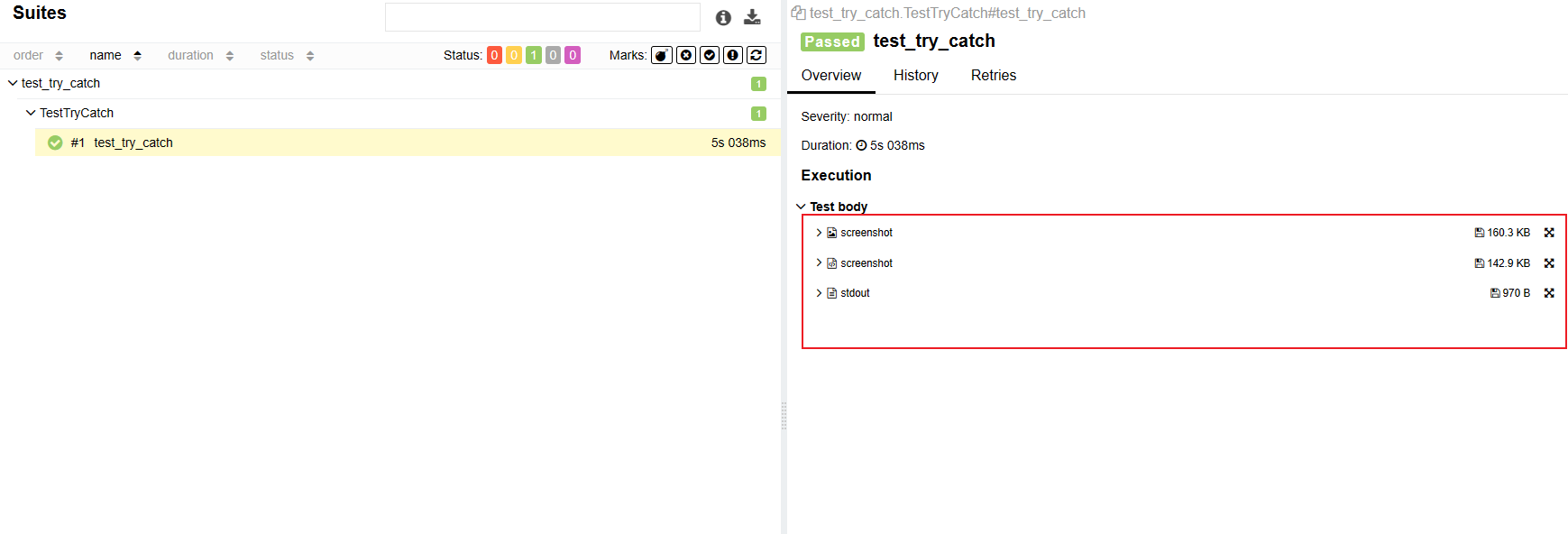
但是刚才的代码比如异常处理的部分其实和业务无关,我们应该怎么处理?
使用装饰器
import allure
from selenium import webdriver
from selenium.webdriver.common.by import By
import time
def ui_exception_record(func):
# 设置
def inner(*args,**kwargs):
# 必须放在方法执行后,不然拿不到driver,因为还没运行 或者放在全局函数
# driver=args[0].driver 这是错误的
try:
func(*args, **kwargs)
# 如果脚本函数需要返回值:
# return func(*args, **kwargs) 其实尽量使用这个更好
except Exception as e:
#获取driver
driver = args[0].driver
# 这里是一定要print的
print("出现异常:", e)
# 获取当前时间
time_stamp = int(time.time())
# 设置截图路径
screenshot_path = f"../data/screenshot/{time_stamp}.PNG"
page_source_path = f"../data/page_source/{time_stamp}.HTML"
# 报存截图
driver.save_screenshot(screenshot_path)
# 保存到测试报告
allure.attach.file(screenshot_path, name="screenshot", attachment_type=allure.attachment_type.PNG)
# 保存page_source
with open(page_source_path, "w", encoding="utf-8") as f:
f.write(driver.page_source)
# 保存到测试报告
allure.attach.file(page_source_path, name="screenshot", attachment_type=allure.attachment_type.HTML)
return inner
# ***********************************************************************
#以上代码可以复用,只要是发生异常,我们就可以实现异常自动截图和page_source获取
class TestTryCatch:
@ui_exception_record
def test_try_catch(self):
#这里的driver一定要是self.driver,被实例化后的
self.driver = webdriver.Chrome()
self.driver.get("https://account.aliyun.com/")
self.driver.find_element(By.ID, 'WE')
self.driver.quit()args[0].driver
是怎么得出来的?
设置定点
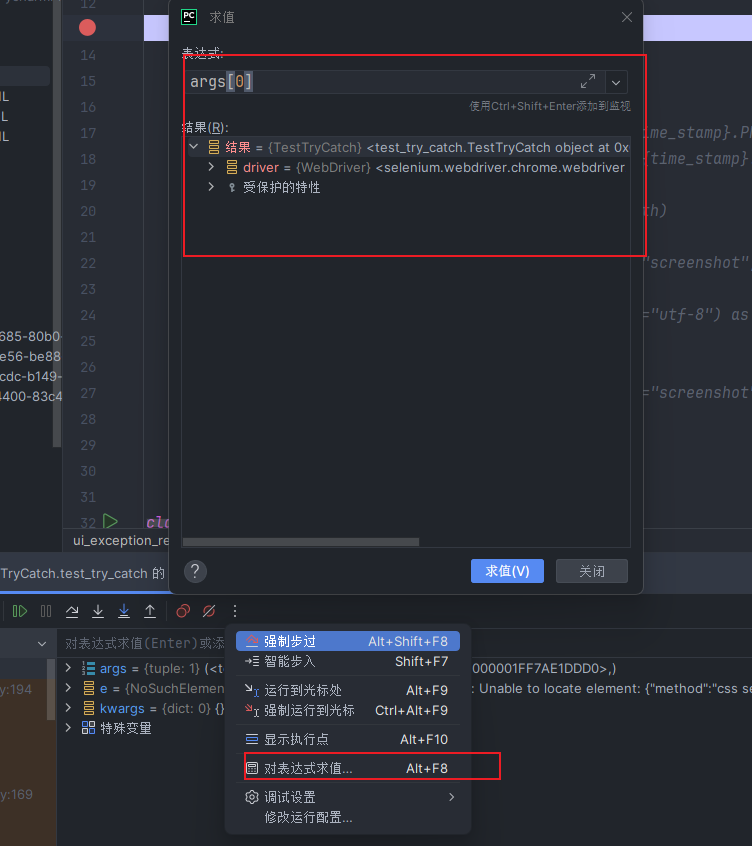
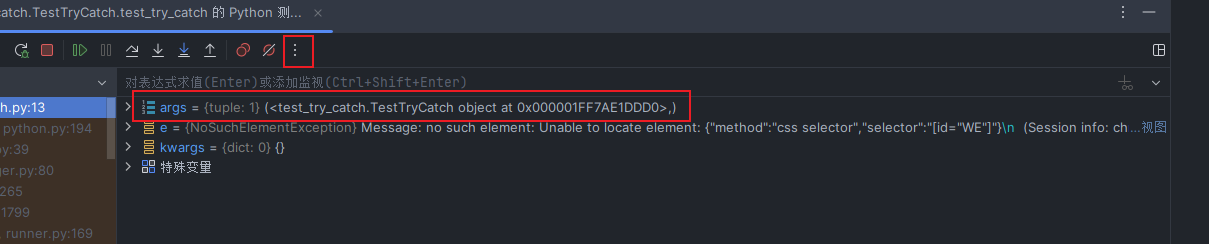 使用求值可以方便定位
使用求值可以方便定位
脚本执行可以写成这样:
class TestTryCatch:
def setup(self):
self.driver = webdriver.Chrome()
@ui_exception_record
def find(self):
self.driver.find_element(By.ID, 'WE')
def test_try_catch(self):
self.driver.get("https://account.aliyun.com/")
self.find()
self.driver.quit()这样就只看find_element有没有报错
这里有个小细节,如果设置了返回值:
def find(self):
return self.driver.find_element(By.ID, 'WE')这个部分得改成:
try:
return func(*args, **kwargs)
except Exception as e:
本文是原创文章,完整转载请注明来自 zhuozhuo
阅读建议

评论
匿名评论
隐私政策
你无需删除空行,直接评论以获取最佳展示效果